
ETH Zurich
ETH Zurich
ETH Zurich
ETH Zurich
ETH Zurich
ETH Zurich
The Fourteenth International Conference on Learning Representations
*Equal Contribution
SOOPER (Safe Online Optimism for Pessimistic Expansion in RL) is a reinforcement learning algorithm designed to ensure safe exploration while learning in real-world environments. SOOPER uses prior policies that can be derived from scarce offline data or simulation under distribution shifts. Such policies are invoked pessimistically during online rollouts to maintain safety. These rollouts are collected optimistically so as to maximize information about a world model of the environment. Using this model, SOOPER constructs a simulated RL environment, used for planning and exploration, whose trajectories terminate once the prior policy is invoked. The key idea is that early terminations incentivize the agent to avoid the prior policy when trajectories with higher returns can be obtained safely. This key idea is illustrated below.
In the example above, the agent’s goal is to reach the cross marker while avoiding obstacles (tires). The agent deploys an exploration policy , however at time , it switches to the prior policy , to maintain the safety criterion . The prior policy ensures safety by following a conservative route, but sacrifices performance, resulting in a lower return . The trajectory of iteration is recorded to improve models of subsequent iterations. After iterations, as more data is gathered, the agent learns a more rewarding trajector via model-generated rollouts that terminate with terminal reward of the expected accumulated future rewards the expected accumulated future reward following the pessimistic prior policy.
Discovering new optimal behaviors require learners to balance between exploring new promising behaviors and exploiting behaviors that are already known to be rewarding. When safety is not required during learning, this “exploration-exploitation” dilemma is known to be efficiently solved by being “optimistic in face of uncertainty”. Intuitively, by assuming that things that we do not know will yield positive outcomes; if we were proved wrong, and outcomes were negative, we acquired new information, and now know not to go there.
In contrast, in safe exploration, we cannot explore freely, but only try out behaviors (or more formally, policies) that we are certain to be safe. More explicitly, we can only explore-exploit within a set that is known to be safe with high probability. Crucially, this set is likely to not include an optimal policy ; optimistic search for an optimal policy will not be enough to find it. Safe exploration techniques solve this challenge with a reward-free pure exploration phase that effectively expands the set of feasible policies.

While pure exploration allows the agent to sufficiently expand the set of feasible policies, performance during this phase can be arbitrarily bad because the learner completely ignores its objective, which specified by the rewards. SOOPER addresses this via intrinsic rewards, namely, rewards that guide the learner to systematically explore even in the absence of (extrinsic) rewards from the real environment. This can be done by solving at each iteration
using model-generated rollouts, where denotes the learner’s uncertainty at a given state-action. The main takeaway is that intrinsic rewards allow us to do both exploration and expansion with a single objective, therefore there is no need for reward-free pure exploration.
We test SOOPER on a five different simulated reinforcement learning environments, comparing it with state-of-the-art safe exploration algorithms. In all of our experiments, we first train a pessimistic prior policy under shifted dynamics. This pessimistic prior policy is known to be safe but due to pessimism, it underperforms when deployed on the true dynamics.

We show that SOOPER can handle control tasks from image observations. Using a CartpoleSwingup setup, the method learns directly from visual embeddings and consistently meets safety constraints while achieving near-optimal performance, even under changes in the environment. As shown, SOOPER (in purple) is the only baseline that satisfies the constraint throughout learning.

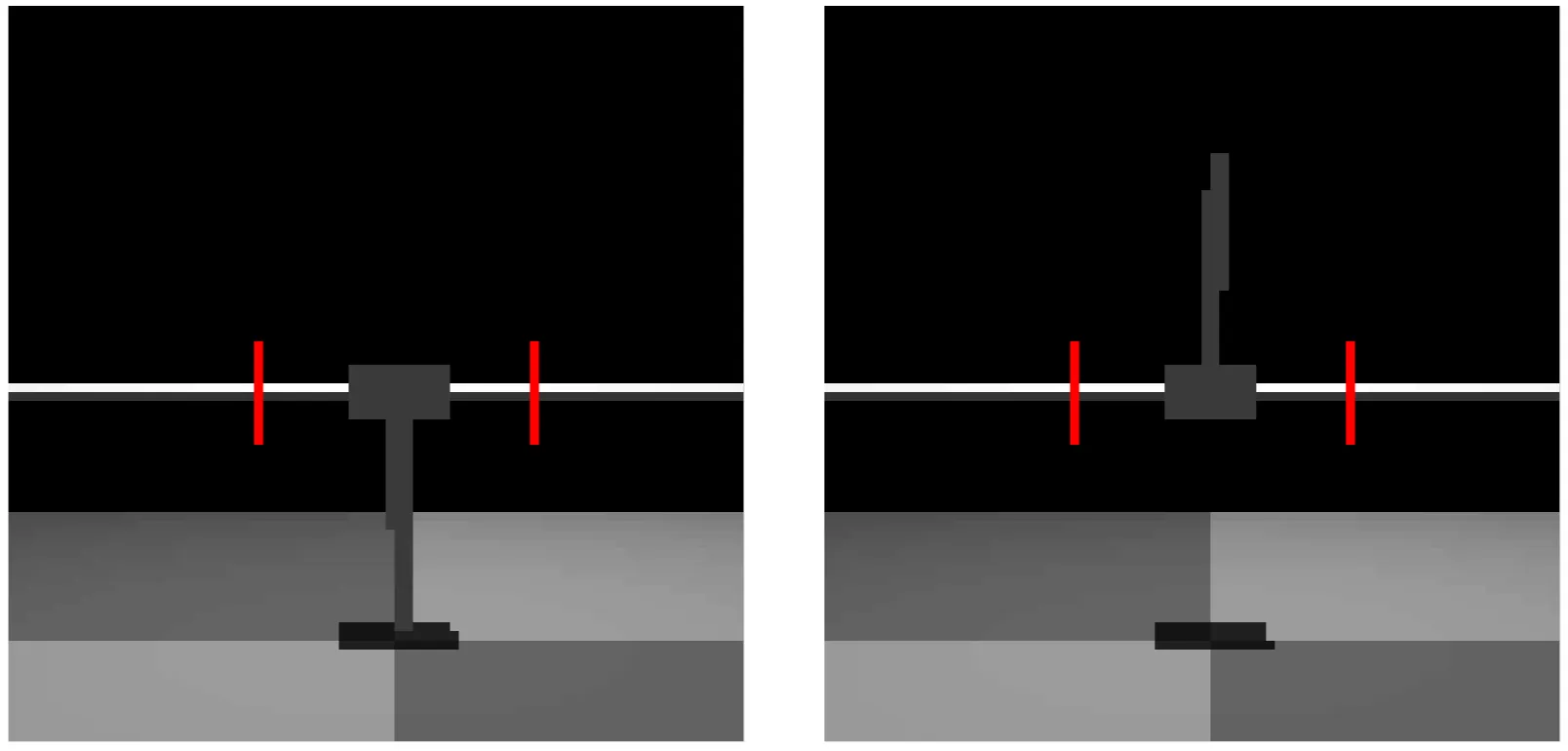
We train a policy using first-principles model of a remote-control racing car that operates at 60 Hz. We then continue training online that policy with SOOPER on real remove control race car using SOOPER.


This experiment is repeated later also by obtaining a prior policy that was trained using expert offline data from the real system.
Check out our open-source implementation for more details. Stay tuned for upcoming paper submissions!
@inproceedings{
wendl2026safe,
title={Safe Exploration via Policy Priors},
author={Manuel Wendl and Yarden As and Manish Prajapat and Anton Pollak and Stelian Coros and Andreas Krause},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=JC8xYAADHL}
}